TINA: The crime hero, A new wonder woman in town.
Hey everyone,
Recently, I along with Abhinand ettan, Anu Chechi, Devi Chechi and Vibhoothi flew all the way to The Netherlands to participate in a hackathon. This hackathon was called hackathon for good and organised by The Municipality of The Hague with the motto to built and find solutions for Peace, Justice and Security. It was our first international hackathon and we were all super excited to spend our 36 hours hacking into an awesome project that we poured our heart and soul into from weeks before the event. In this short blog post, I will mainly focus on to describe what our hack was on and what we hacked during the entire 36 hours. Here we go ;)

We all are worried about dangerous people walking down the street just because we cannot read the information fast enough. As part of the evidence gathering and analysis process, the International Criminal Court has to analyse a number of written documents which can be a huge data set containing various information. The analysis is completely manual. The International Criminal Court has to go through all these information manually, figure out various entities from each file and layout relationships between those entities. Because of this slow and manual process, criminals spend more time outside rather than doing their time inside their cells. As this is a major issue the world is facing, so International Criminal Court had hosted a Challenge in the Hackathon for Peace Justice and Security.
Henceforth, we thought to pick this up because we felt that we could actually help to solve this problem. Even this being a tedious task, the thought that our solution would highly benefit lives of people at International criminal court and to help citizens of our nation to walk around freely in their neighbourhood without being scared of such criminals was the best motivation we had.

We introduced a hack, which we named TINA(Text mIning aNalysis dAtabase) to address this problem, yes we know that sounds a bit weird, that is weird Acronym.
TINA aimed at helping the International Criminal Court, by providing a simple, yet conclusive and complete automated application which takes care of all the Witness statements, NGO Reports, Media Articles, and much more and produce the expected entities along with the relationships it possessed by the application of various Machine Learning, Artificial Intelligence and deep learning techniques which is served as a whole package under the name of TINA.
What International criminal court expected was just a node + edge graphical representation stored over graphical database format – such as a .json file or a .csv. But as a team, we thought this isn’t enough. This can provide the International criminal court to identify the entities and relationships among the information but it wouldn’t speed up the process as it should be because we are talking about a very large dataset with the very high number of nodes and edges representing a crime alone maybe.
Henceforth, we decided to make sure Tina represent the data and visualise them in ways that would not only help to identify entities or the relationships that exists but will list the entire details in a dashboard. We included multiple features into the dashboard such as Crime Heat Map, Google Maps based Location Searching, Smart Table, Graphical Representation of the Data Extracted.
With the aim to provide a complete automated package to the International criminal court, we broke down the entire process into different parts for the application:
- Evidence Analysis
- Extractor part
- The dashboard
- The Core (ML/NLP)
Evidence Analysis
This section could be considered as a formal training for ourselves to identify the core aspect of the project. As a part of Evidence analysis, we tried hard to gather as much as dataset get some valid data to train our models. The process to understand the dataset provided by the ICC was hard until an extend - mainly because we only saw very less usable data points that can be used to layout the model. Henceforth, we decided to spend a considerable amount of our time during the hackathon just to find out dataset that could at least be used to as an example to train. We faced some amount of difficulty to find various resources from where we will get such important documents, even if it be bogus. But we were successful up to an extent to collect enough dataset for our project to train for but we couldn’t expect much rate of accuracy from those datasets though.
The Extractor
Next, it was about how to collectively process this entire dataset that the International criminal court would have. Since it these documents was of different file formats, we had to process them. Further, International criminal court would have this as a dataset of 10s or 100s of GB, so it would be highly unlikely for them to process them one by one. So, built an API which can take all the files like PDF, docx, txt and jpg irrespective of its file type and makes it to text which could be passed on to the next module of TINA. The input for this API can also be some folder, it will provide the OTP more flexibility like never before. The folder can contain any sort of data which is needed to be extracted. We went a bit out of the scope for giving a better User Experience (UX.). The Extractor can also take inputs as a URLs or any sort of web links to the Office of the Prosecutor at International criminal court can have an easier way to feed information directly through the internet. In the future, we are planning to integrate a proper Google Search feature inside the dashboard so instead of the linking, a whole new option which will be easier. Then after the extraction, we will be writing this into different files and also in a single file which appends all results as TXT along with the file metadata so that we don’t lose any information regarding a crime that can be useful in all ways possible. After parsing, this text file is passed to the Core module of Tina where the ML and NLP are processed and the detailed things about that later in this post below. Below you may find a snapshot of how our Office of the Prosecutor at International criminal court could interact with the extractor API through our dashboard.
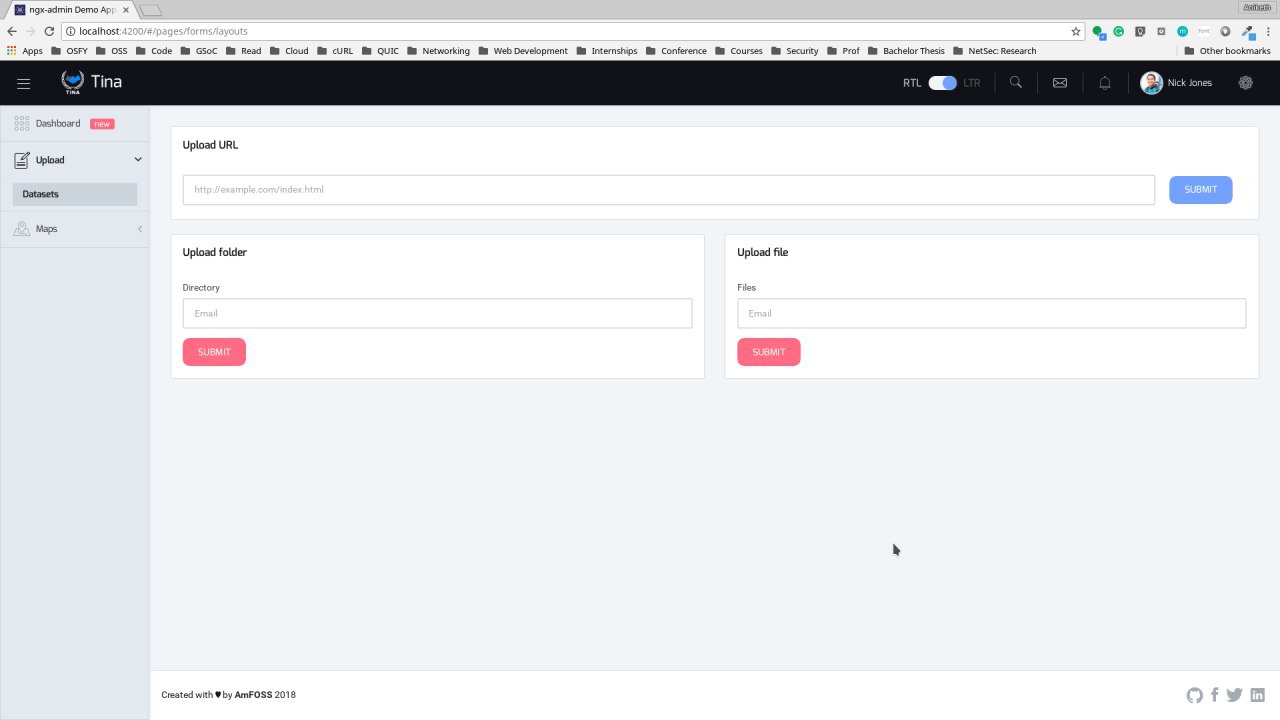
The Dashboard
The dashboard is the core aspect of our project, We have specially designed the Dashboard with only one thing in mind that everyone who is 20 or who is 70 can use at the same time without being complex. That is, we really wanted our tool to be easy to use and doesn’t require someone to read through huge documentations to have a basic understanding of how to use it. For Instance, a person who doesn’t have much knowledge on understanding the directed Graphs it will be nearly not possible for him to read from the graph so we made integration of Google Maps for showing the Crime Location instead of showing the Location as a label. We have lots of numbers in where X person Killed Y people so we made that as an input for visual Graph. Also, we have made a special Heat Map of Crime, where all global crime details are shown. Below, you can find a few screenshots of how the dataset is being represented in various forms through our dashboard.

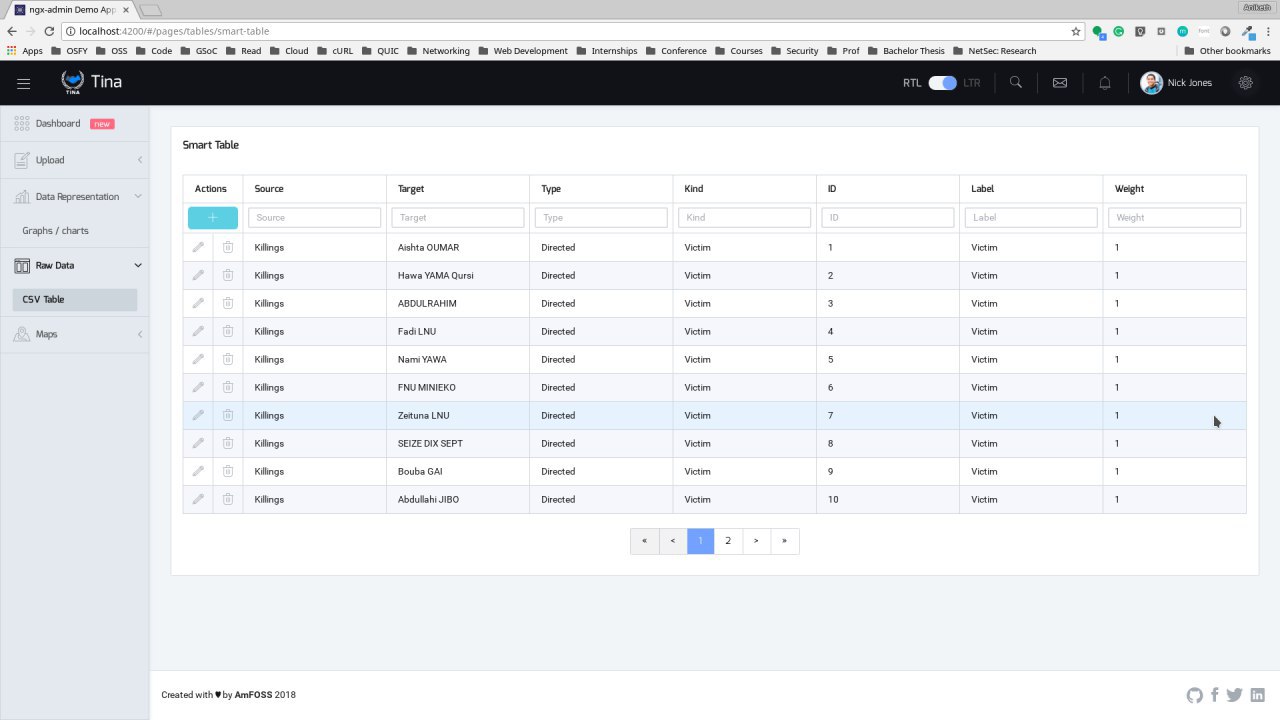


The Core( ML/NLP)
The core part of the project mainly focuses on automating the process of analyzing the evidence of various crimes that needed to be handled by ICC. After The extractor API did its black magic, the text is moved into the ML module to extract entities and find relationships between them in the context of ICC easily. While coding, we made use of various python packages like Spacy, nltk, keras. numpy and sklearn to do the needful. In order to achieve the process of identifying entities (or nodes) such as events, dates, places etc, we have used an approach which can provide better results. spaCy is one of the powerful natural language processing tools which excels at large-scale information extraction tasks. Combining the power of spaCy with LSTM to identify the nodes was one of the novel methods which we have used in this tool. Moreover using the output from spaCy as an input to LSTM gave us better results in cherry picking entities from the huge amount of text data.
One of the main challenges was that we had very less ground truth or factual data that were given to us. We focused on designing a better model which would work with a very minimal amount of data and further produce better results. We used the classification technique in order to train the model for classifying the relationships. So when a new data is fed to the model it will classify the relationship among the entities. For eg: it will classify that event and date is connected ie the event happened on XYZ date.
Keeping future in mind, if we plan to improve the model even further by using character-level embeddings we could use used implementation provided by the keras-contrib package, that contains useful extensions to the official keras package where it could also help to have a large number of datasets with more complicated named entities to have a stronger and well-trained model.
The technical stack
As a techie, this blog post is only half done without TINA’s technical stack ;)
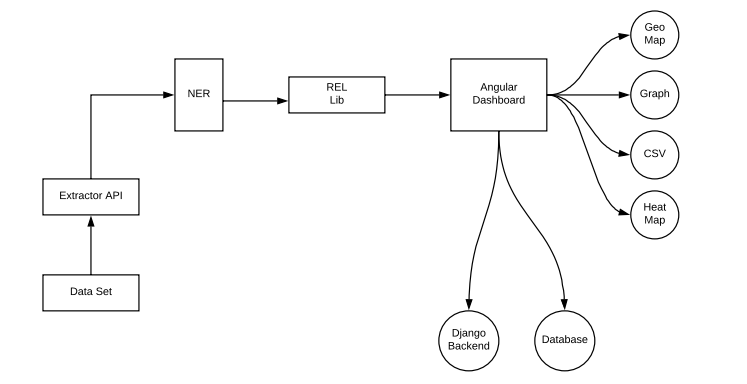
The above figure illustrates the entire workflow of TINA in one place. Providing a brief explanation on this: At first, we have the entire dataset, let it be files of any kind - PDF, DOC(X) etc, this can be all in just one folder. It is then dumped into the Extractor API. All the black magic to extract the texts from those various files will be taken care of by the Extractor API. Further, the results from the API to the NER and REL module. Where NER module makes use of classical Natural Language Processing methodologies to extract various entities from the texts. Further, the REL Library makes sure the extracted entities have a better contextual meaning and finds a relationship with the entities extracted. Algorithms like LSTM works behind this library to help us to do that. Finally, we draw all our inferences through either via Geo Maps, graphs, CSV or heatmap through the dashboard that we designed using by Angular 6, Typescript as front-end stack and Django python web framework to support the backend.
You can find the Codebase here: https://gitlab.com/Aniketh01/tina
Cheers.